

Expanded microbial genome coverage and improved protein family annotation in the COG database
- PMID: 25428365
- PMCID: PMC4383993
- DOI: 10.1093/nar/gku1223
Expanded microbial genome coverage and improved protein family annotation in the COG database
Abstract
Microbial genome sequencing projects produce numerous sequences of deduced proteins, only a small fraction of which have been or will ever be studied experimentally. This leaves sequence analysis as the only feasible way to annotate these proteins and assign to them tentative functions. The Clusters of Orthologous Groups of proteins (COGs) database (http://www.ncbi.nlm.nih.gov/COG/), first created in 1997, has been a popular tool for functional annotation. Its success was largely based on (i) its reliance on complete microbial genomes, which allowed reliable assignment of orthologs and paralogs for most genes; (ii) orthology-based approach, which used the function(s) of the characterized member(s) of the protein family (COG) to assign function(s) to the entire set of carefully identified orthologs and describe the range of potential functions when there were more than one; and (iii) careful manual curation of the annotation of the COGs, aimed at detailed prediction of the biological function(s) for each COG while avoiding annotation errors and overprediction. Here we present an update of the COGs, the first since 2003, and a comprehensive revision of the COG annotations and expansion of the genome coverage to include representative complete genomes from all bacterial and archaeal lineages down to the genus level. This re-analysis of the COGs shows that the original COG assignments had an error rate below 0.5% and allows an assessment of the progress in functional genomics in the past 12 years. During this time, functions of many previously uncharacterized COGs have been elucidated and tentative functional assignments of many COGs have been validated, either by targeted experiments or through the use of high-throughput methods. A particularly important development is the assignment of functions to several widespread, conserved proteins many of which turned out to participate in translation, in particular rRNA maturation and tRNA modification. The new version of the COGs is expected to become an important tool for microbial genomics.
Published by Oxford University Press on behalf of Nucleic Acids Research 2014. This work is written by US Government employees and is in the public domain in the US.
Figures
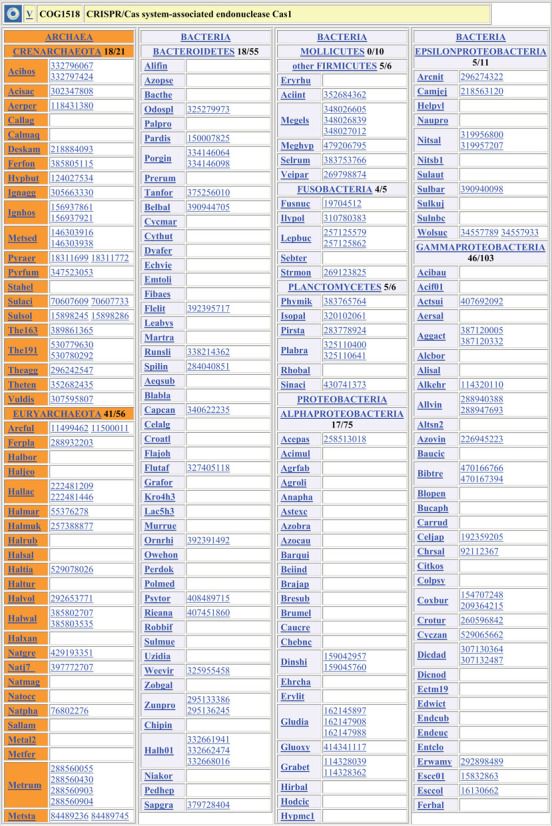
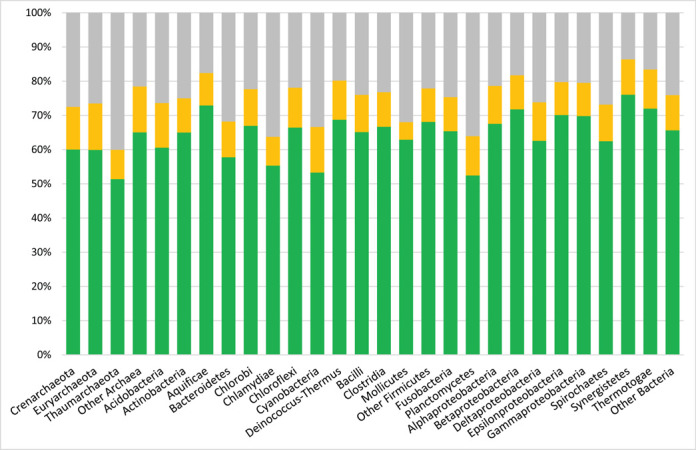
Similar articles
-
COG database update: focus on microbial diversity, model organisms, and widespread pathogens.Nucleic Acids Res. 2021 Jan 8;49(D1):D274-D281. doi: 10.1093/nar/gkaa1018. Nucleic Acids Res. 2021. PMID: 33167031 Free PMC article.
-
Clusters of orthologous genes for 41 archaeal genomes and implications for evolutionary genomics of archaea.Biol Direct. 2007 Nov 27;2:33. doi: 10.1186/1745-6150-2-33. Biol Direct. 2007. PMID: 18042280 Free PMC article.
-
Microbial genome analysis: the COG approach.Brief Bioinform. 2019 Jul 19;20(4):1063-1070. doi: 10.1093/bib/bbx117. Brief Bioinform. 2019. PMID: 28968633 Free PMC article. Review.
-
The COG database: a tool for genome-scale analysis of protein functions and evolution.Nucleic Acids Res. 2000 Jan 1;28(1):33-6. doi: 10.1093/nar/28.1.33. Nucleic Acids Res. 2000. PMID: 10592175 Free PMC article.
-
A genomic perspective on protein families.Science. 1997 Oct 24;278(5338):631-7. doi: 10.1126/science.278.5338.631. Science. 1997. PMID: 9381173 Review.
Cited by
-
Comparative Genomics, from the Annotated Genome to Valuable Biological Information: A Case Study.Methods Mol Biol. 2021;2242:91-112. doi: 10.1007/978-1-0716-1099-2_7. Methods Mol Biol. 2021. PMID: 33961220
-
Metagenomic functional profiling: to sketch or not to sketch?Bioinformatics. 2024 Sep 1;40(Suppl 2):ii165-ii173. doi: 10.1093/bioinformatics/btae397. Bioinformatics. 2024. PMID: 39230701 Free PMC article.
-
Hohaiivirga grylli gen. nov., sp. nov., a New Member of the Family Methylobacteriaceae, Isolated from Cricket (Gryllus chinensis).Curr Microbiol. 2024 Oct 6;81(11):392. doi: 10.1007/s00284-024-03922-3. Curr Microbiol. 2024. PMID: 39369359
-
The marine environmental microbiome mediates physiological outcomes in host nematodes.BMC Biol. 2024 Oct 8;22(1):224. doi: 10.1186/s12915-024-02021-w. BMC Biol. 2024. PMID: 39379910 Free PMC article.
-
The Evolutionary Kaleidoscope of Rhodopsins.mSystems. 2022 Oct 26;7(5):e0040522. doi: 10.1128/msystems.00405-22. Epub 2022 Sep 19. mSystems. 2022. PMID: 36121162 Free PMC article.
References
-
- Tatusov R.L., Koonin E.V., Lipman D.J. A genomic perspective on protein families. Science. 1997;278:631–637. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Molecular Biology Databases
Miscellaneous
